Введение
В этой заметке будут опущены тонкости трансляции адресов. Также в ней опущены тонкости первичной инициализации памяти (выделение двух страниц, статические данные и т.п.). Память, которая не относится к первичной инициализации называется динамической. Именно управление ею и будет рассмотрено в данной заметке.
Управление динамической памятью — важная составляющая эффективности работы системы. Памятью пользуются не только процессы, но и ядро ОС(файловый кэш, буферы периферийных устройств, и т.п.). Данная заметка будет как раз про то, как ядро управляет памятью для своих нужд.
Управление страницами памяти
Традиционно, страницы памяти в Linux имеют размер в 4 КиБ. В зависимости от архитектуры этот размер может меняться. Aarch64, например, поддерживает до 64 КиБ. Это мы сейчас не говорим про так называемые hugepages. Почему именно 4 КиБ является стандартом:
- Работать с исключениями
Page Faultпроще: меньший размер кадра можно найти чаще. - Работа с постоянной памятью происходит эффективнее с блоками памяти меньшего размера.
Дескрипторы страниц
Задача ядра ОС: управлять ресурсами машины и разделять их между пользователями этих ресурсов. То есть, ядро ОС должно иметь возможность следить за каждым кадром памяти таким образом, чтобы было понятно: занята ли эта страница, принадлежит ли она какому-либо процессу пользовательского пространства, каким образом с ней следует работать и т.д. Определение такой структуры находится в файле include/linux/mm_types.h:
struct page {
unsigned long flags; /* флаги, описывающие состояние страницы */
...
atomic_t _refcount; /* счётчик ссылок на страницу */
...
} _struct_page_alignment;
_refcount— поле, отражающее использование этой страницы. Работа с ним происходит через методы, описанные вinclude/linux/page_ref.h.flags— в этом поле можно найти как состояние страницы, так и зону, к которой страница относится. Полное и актуальное описание можно найти в файлеinclude/linux/page-flags.h.
Non-Uniform Memory Access (NUMA)
Доступ к памяти, даже оперативной, является довольно дорогим удовольствием, и платят за него временем. В некоторых системах доступ к памяти может не быть однородным: например, интерфейс к каким-то конкретным банкам памяти у одного ядра может быстрее, чем у второго, а к другим банкам памяти наоборот — второе ядро процессора быстрее доступится до других банков памяти, чем первое. Если процессорный кэш можно просто физически разделить по разным ядрам, то с оперативной памятью сделать это скрытно от ОС не получится, т.к. она вся целиком лежит в общем пространстве памяти, а её пользователи (пользовательские процессы, потоки ядра) могут мигрировать с одного ядра на другое.
Чтобы корректно учесть этот факт при управлении памятью и повысить эффективность доступа к ней, придумали механизм NUMA. Его суть заключается в разделении пространства памяти на некоторые диапазоны адресов(называемые нодами или узлами), и при выделении новой памяти отдавать предпочтения тем страницам, которые лежат в узле, доступ к которым будет наиболее эффективным. Доступ к памяти внутри одного узла считается однородным.
С точки зрения ядра Linux, существуют следующая структура данных, описывающая : struct pglist_data, она же pg_data_t. Найти её можно в файле include/linux/page-flags.h. Для машин с однородным доступом к памяти будет выделен всего один экземпляр такой структуры, описывающий всю память.
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; /* массив всех используемых зон памяти в этой ноде */
struct zonelist node_zonelists[MAX_ZONELISTS]; /* массив всех зон во всех нодах, местные зоны, обычно, первые */
int nr_zones; /* количество используемых зон памяти в этой ноде */
#ifdef CONFIG_FLAT_NODE_MEM_MAP
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
...
} pg_data_t;
Получить первый(как младший бит в битовом поле) активный узел можно через эту функцию:
struct pglist_data *first_online_pgdat(void);
{
return NODE_DATA(first_online_node);
}
Макрос NODE_DATA определяется для каждой архитектуры отдельно. Например, для Aarch64 он определён в файле arch/arm64/include/asm/mmzone.h:
extern struct pglist_data *node_data[];
#define NODE_DATA(nid) (node_data[(nid)])
То есть, для Aarch64 все узлы NUMA хранятся в массиве указателей node_data.
Зоны памяти
В идеальном мире хотелось бы видеть такое, что любой кусочек памяти можно было бы использовать для любой задачи. Однако, в нашем мире это не так. Может быть множество ограничений, связанных с этим. В основном они утыкаются в адресное пространство:
- Старые устройства, использующие DMA для обмена данными, могут не быть способными использовать такое большое адресное пространство, какое имеется у современных компьютеров.
- Ещё до перехода от 32-битных систем к 64-битным была актуальна проблема того же адресного пространства: технологии позволяли дать машине больше памяти, чем она могла адресовать. С мощнейших серверов эта проблема перешла и домашним ПК.
- Некоторые специфичные конкретной архитектуре аппаратные возможности могут иметь ограничение по всё тому же адресному пространству: либо необходимы конкретные адреса, либо размер этого диапазона ограничен. Например,
ARMиAarch64, использующие AXI-интерфейсы для доступа к памяти, имеют выделенный AXI-интерфейс для DMA, называемый ACP: он позволяет ходить за данными в процессорный кэш, что сильно увеличивает эффективность системы, т.к. больше нет нужды программно следить за когерентностью кэшей и постоянной памяти. Однако, он накладывает ограничение на адресное пространство: я встречал реализации с нижними 256 МиБ и 512 МиБ адресов.
Для обхода таких ограничений, разработчики ядра Linux приняли решение поделить память на зоны. Список таких зон перечислен в файле include/linux/mmzone.h:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
Как видно, безусловно будет только две зоны: ZONE_NORMAL и ZONE_MOVABLE. Само ядро Linux может непосредственно адресовать только ZONE_NORMAL и зоны ZONE_DMA*, если они имеются.
ZONE_DMA — довольно старая зона, когда ещё можно было встретить, например, ISA шину, которая не могла адресовать память выше 16 МиБ. Обычно, ограничена этими 16 МиБ, однако её можно настроить для некоторых платформ.
ZONE_DMA32 — как можно понять из названия, зона обеспечивает адресацию по 32-битному адресу, на случай если ваши периферийные устройства имеют такое ограничение.
ZONE_NORMAL — обычная память, доступная как ядру, так и пользовательскому пространству. DMA также может использовать и эту память, если устройство такое умеет.
ZONE_HIGHMEM — память, которая не может быть непосредственно адресована ядром ОС. Если такая зона присутствует, то Linux должен будет спроецировать область памяти в своё адресное пространство, чтобы воспользоваться ей.
ZONE_MOVABLE — память, идентичная ZONE_NORMAL за тем исключением, что в ней не гарантируется перманентное соответствие области памяти (данных) физическому диапазону адресов. То есть, память в этой зоне может быть отключена/включена и/или перемещена в ходе работы системы. Такое, например, может быть полезно для паравиртуализации.
ZONE_DEVICE — память в этой зоне скорее является проекцией блочного устройства на физическую память (объяснений в файле нет, но так пишет автор правки в коммите 033fbae988fc ("mm: ZONE_DEVICE for "device memory"")). Чтобы исключить выделения памяти в этой области, и добавлена зона ZONE_DEVICE.
… проблема того же адресного пространства: технологии позволяли дать машине больше памяти
То есть, проблема того, что компьютер имеет недостаточное адресное пространство для адресации всей памяти, решается помещением излишков в ZONE_HIGHMEM. Пользовательский процесс имеет свою таблицу трансляции адресов, то есть, он всегда сможет адресовать свои 4 ГиБ памяти. Получается, один процесс пользует свои 4 ГиБ, второй процесс — другие свои 4 ГиБ, а ядро всегда способно спроецировать любой отрезок физической памяти в своё адресное пространство.
Старые устройства, использующие DMA для обмена данными, могут не быть способными использовать такое большое адресное пространство, какое имеется у современных компьютеров.
Некоторые специфичные конкретной архитектуре аппаратные возможности могут иметь ограничение по всё тому же адресному пространству.
А эта проблема решается выделением памяти из зон ZONE_DMA или ZONE_DMA32. Немного забегая вперёд, хочу сказать, что это не всегда решается таким образом (См. #swiotlb).
Дескриптором же каждой такой зоны является структура struct zone, которая описана в файле include/linux/mmzone.h:
struct zone {
#ifdef CONFIG_NUMA
int node; /* номер узла, если используется NUMA */
#endif
struct pglist_data *zone_pgdat; /* указатель на узел памяти, которому принадлежит эта зона */
...
unsigned long zone_start_pfn; /* номер первой страницы в данной зоне */
atomic_long_t managed_pages; /* количество страниц под управлением Buddy аллокатора */
unsigned long spanned_pages; /* протяжённость зоны в штуках страниц, включая дыры */
unsigned long present_pages; /* количество физических страниц (то есть, исключая дыры) */
const char *name; /* имя зоны */
...
struct free_area free_area[MAX_ORDER]; /* группы Buddy аллокатора в данной зоне */
unsigned long flags; /* В v5.10 есть только один флаг: ZONE_BOOSTED_WATERMARK */
...
}
Когда ядро просит аллокатор выделить память, оно может явно указать зону, из которой она хочет взять память. Однако, если память выделить из указанной зоны невозможно, то аллокатор попытается взять память из нижестоящей (то есть, по убыванию в приведённом выше перечислении).
swiotlb
Разработчики аппаратной архитектуры Intel Itanium подошли к этому с другой стороны. Дело в том, что память в зонах ZONE_DMA* всё ещё может быть отдана под задачи ядра или пользовательскому процессу в случаях, когда выделение из вышестоящих зон невозможно. Для избежания подобных ситуаций в ядро был добавлен механизм swiotlb (Software I/O TLB). Суть механизма заключается в том, чтобы зарезервировать нижний диапазон адресов и таким образом исключить его из стандартного процесса управления памятью ядра ОС на раннем этапе загрузки машины. Тогда, драйвер устройства может попросить swiotlb спроецировать выделенную ему память на те адреса, которые были зарезервированы.
Зарезервированная память
Запрос на выделение памяти может быть удовлетворён двумя путями: либо свободная память есть, и тогда эта свободная память отдаётся её пользователю; либо свободной памяти нет, и тогда необходимо выполнить рутину, которая займётся освобождением памяти, чтобы удовлетворить запрос. Например, нам необходимо выделить несколько гигабайт памяти, однако память занята файловым кэшем (допустим, мы кино смотрели, а теперь хотим посмотреть другое). В таком случае, нам необходимо выгрузить из оперативной памяти те файлы, которые нам уже не нужны.
Но есть нюанс, и абзац выше справедлив не для каждого запроса на выделение памяти. Например, обработчики аппаратных прерываний (hardirq) не могут себе позволить ждать, пока ядро ОС разберётся с тем же файловым кэшем. Поэтому особенно чувствительные ко времени исполнения рутины ядра используют так называемые атомарные операции выделения памяти. Чтобы выделить память атомарно, достаточно указать флаг GFP_ATOMIC для kmalloc. Такая операция либо завершится немедленно, либо завершится с ошибкой.
С учётом того, что наш разделяемый ресурс не может являться бесконечным, нельзя гарантировать, что атомарный запрос на выделение память всегда будет успешно удовлетворён. Однако, можно минимизировать количество ошибок путём резервирования памяти заблаговременно — этим приёмом и воспользовались разработчики ядра Linux. На старте машины сначала рассчитывается объём необходимой памяти. Делается это функцией calculate_min_free_kbytes в файле mm/page_alloc.c. Суть её исчислений сводится к следующей формуле:
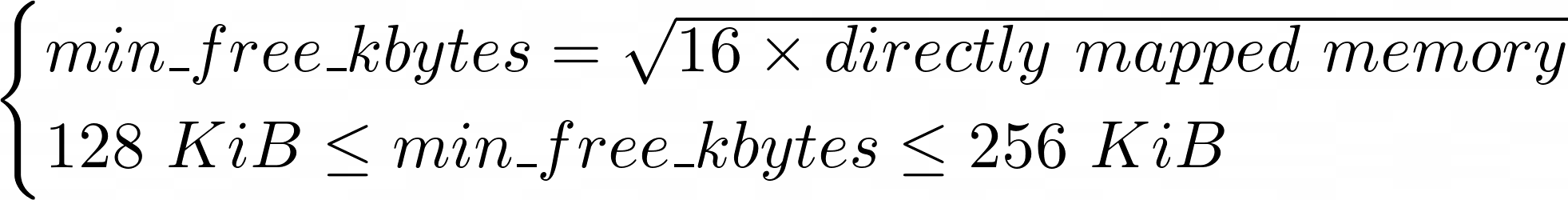
Да, есть ограничения на размер такого пула зарезервированной памяти. Оно долго не менялось и было изменено только совсем недавно, в коммите ee8eb9a5fe86 ("mm/page_alloc: increase default min_free_kbytes bound"). Как пишет сам автор правки:
это значение (64 КиБ) не менялось с 2005-ого года, в то время как мощные серверы заимели сотни ГиБ оперативной памяти и имеют на борту множество сетевых карточек по 100 Гб/с.
На самом деле, эта правка не то что бы капитально исправила ситуацию: речь, ведь, про начальный расчёт этого значения. Во время работы ничто не мешает обновить это значение без ограничений через sysctl. В любом случае, это значение пересчитывается в количество страниц, распределяется поровну между зонами памяти а затем записывается в поле zone->_watermark — значения, которое используется как критерий для решения об освобождении памяти (см. mm/page_alloc.c: __setup_per_zone_wmarks).