Аннотация
Если при отладке зависшего ядра на AArch64 вы видите в
стеке __switch_to, не спешите искать ошибку в планировщике
— скорее всего, бэктрейс просто врёт. В статье разбираем, почему на
системах без поддержки NMI механизм dump_backtrace вынужден
читать устаревший контекст из task_struct, как именно
работает низкоуровневое переключение задач и почему
наличие __switch_to в выводе — это верный признак того, что
перед вами не реальный стек вызовов, а “цифровой призрак” из
прошлого.
Введение
Данная заметка должна поднять завесу тайны над сущностью ядра Linux, которая называется “generic net estimator”. Зачем это нужно, и как этим пользоваться?
Ладно, дальше всё равно будет каша, потом структурирую.
Кликни по мне, чтобы перейти к полному тексту...Введение
В данной заметке речь пойдёт об отображении кадров страниц памяти из ZONE_HIGHMEM на линейное адресное пространство ядра. Как было упомянуто в Управление памятью#Зоны памяти, ядро не может непосредственно адресовать память из ZONE_HIGHMEM. Чтобы ядро могло получить доступ до этой памяти и нужно её отображение в адресное пространство ядра.
На современных ПК, в том числе смартфонах, вряд ли уже можно встретить ZONE_HIGHMEM, т.к. 64-битные платформы не имеют ограничение по адресному пространству. Однако, представленный механизм имеет место в Linux v5.17, т.к. 32-битные платформы из нашей жизни не исчезли: кто знает, сколько Aarch32-/MIPS32-роутеров, работающих на Linux, пересекла эта страница, прежде чем попасть в браузер.
Введение
Подсистема ядра, которая удовлетворяет запросы на выделение памяти называется зонированным аллокатором страничных кадров, — если переводить дословно. Давайте взглянем на небольшую диаграмму:
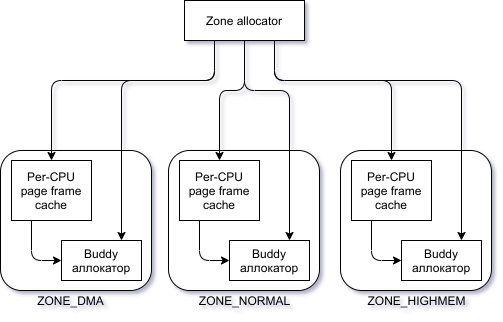
Компонент Zone allocator получает запросы на выделение и освобождение динамической памяти. В случае с выделением, этот компонент сначала определит зону, которая могла бы удовлетворить запрос. Допустим, мы хотим выделить память под кольцевой буфер сетевой карты, то есть мы передали флаг GFP_DMA. Тогда, Zone allocator может взять память только из зоны ZONE_DMA (т.к. флаг GFP_DMA требует выделения памяти из зоны ZONE_DMA). Если бы мы не передали этот флаг, то Zone allocator сначала поискал бы свободную память в зоне ZONE_NORMAL (но не в зоне ZONE_HIGHMEM, т.к. мы не указали флаг __GFP_HIGHMEM, который указывает, что память может быть выделена в ZONE_HIGHMEM, но не требует этого).
Внутри каждой зоны есть компонент Buddy allocator, который и управляет страницами памяти (см. Buddy аллокатор). Однако, для увеличения быстродействия системы, запрос может быть удовлетворён страницами из кэша, который отражён на диаграмме компонентном Per-CPU page frame cache. Правда, в кэше обычно лишь небольшое количество страниц.
Предыстория этой заметки
Пока не вижу её будущего, но не могу записать это в ту, которую сейчас пишу. В общем, я сломался об исходный код, а оказалось, что всё макросами генерится.
Кликни по мне, чтобы перейти к полному тексту...Введение
В этой заметке будут опущены тонкости трансляции адресов. Также в ней опущены тонкости первичной инициализации памяти (выделение двух страниц, статические данные и т.п.). Память, которая не относится к первичной инициализации называется динамической. Именно управление ею и будет рассмотрено в данной заметке.
Управление динамической памятью — важная составляющая эффективности работы системы. Памятью пользуются не только процессы, но и ядро ОС(файловый кэш, буферы периферийных устройств, и т.п.). Данная заметка будет как раз про то, как ядро управляет памятью для своих нужд.
Кликни по мне, чтобы перейти к полному тексту...Введение
Существует проблема при управлении памятью, которая заключается в том, что выделения и освобождения участков разных размеров приводят к фрагментации свободной памяти. Таким образом, несмотря на достаточный объём свободной памяти, может быть невозможным выделение непрерывного участка памяти требуемого размера — назовём это негативным эффектом фрагментации.
Для того, чтобы избежать негативного эффект от фрагментации, можно:
- Спроецировать несколько участков свободной памяти в один непрерывный диапазон виртуальных адресов.
- Отслеживать управление памятью, вести учёт освобождённых участков памяти и стараться избегать разбиение больших участков на меньшие участки.
Оба варианта дорогие. У второго это по формулировке видно, а первый так или иначе потребует трансляции адресов (хорошо, если аппаратной) и управление этой трансляцией для каждого выделенного кусочка памяти.
Ядро предпочло второй вариант. На это есть несколько причин:
- Не всегда достаточно непрерывного участка линейного адресного пространства, иногда нужен именно непрерывный участок физической памяти. Например, для DMA, большинство реализаций которого не смогут транслировать адрес. Хотя да, есть аппаратные средства, например, у ARM это SMMU(System Memory Management Unit), который позволяет транслировать адреса как со стороны CPU, так и со стороны других подсистем машины. В частности, это помогает реализовывать виртуализацию аппаратных блоков, а также полезно для DPDK.
- Для реализации проецирования памяти пришлось бы реализовать механизм, который бы часто изменял таблицу страниц памяти, которая отвечает за трансляцию, что привело бы к повышению среднего времени доступа к памяти. Это не совсем очевидно, но чтобы обновить таблицу трансляций, нужно также очистить кэш как на локальном, так и на остальных CPU, т.к. в момент изменения таблицы трансляций, записи в кэше станут невалидными (физический адрес записи в кэше мог поменяться).
- Большие участки физической памяти могут быть доступны через страницы по 4 МБ, что сокращает промахи в TLB (Translation Lookaside Buffer). Таким образом, уменьшается среднее время доступа к памяти.
Разработчики Linux назвали свой алгоритм "buddy memory allocation" в честь так называемой "системы приятелей". Система приятелей заключается в том, что два человека могут объединить усилия в каком-либо деле, тем самым контролируя друг друга.
В рамках этого алгоритма все свободные страницы формируются в группы по 1,2,4,8..1024 (и т.д., в зависимости от аппаратной платформы) блоков. Начальный адрес каждой группы является произведением размера этой группы. Например, для группы по 16 страниц начальным адресом будет 16 * 2^12, где 2^12 — типичный размер страницы в 4 КБ. Понятно, что речь идёт о смещение относительно некоторого начала памяти для buddy allocator.
Приведу пример работы этого алгоритма:
Допустим, мы хотим выделить 1 МБ непрерывной физической памяти, то есть 256 страниц. Первым делом алгоритм проверит наличие свободного блока по 256 страниц. Если такой блок есть, то алгоритм отдаёт его, и работа закончена. Если такого блока нет, то алгоритм будет искать свободный блок по 512 страниц. Если такой блок есть, то алгоритм разобьёт его на два блока по 256 страниц, один отдаст пользователю, второй сохранит в группе других блоков по 256 страниц. Если и по 512 страниц блока не нашлось, тогда алгоритм попробует найти блок по 1024 страницы. Таким образом, блок по 1024 страницы будет разбит на три блока: один по 512, два по 256. Как только алгоритм дошёл до группы наибольшего размера и не нашёл свободной памяти, способной удовлетворить запрос, алгоритм безуспешно завершает свою работу и сигнализирует об ошибке.
Обратное действие — освобождение памяти — отсылает к названию алгоритма. Если мы хотим освободить участок непрерывной памяти размером в 1 МБ, то алгоритм попытается найти рядом свободный блок такого же размера и слить их в один блок. Таким образом, если рядом с только что освобождённым блоком по 256 страниц имеется ещё один блок по 256 страниц, то алгоритм объединит их в один блок по 512 страниц. В свою очередь, новообразованный блок по 512 страниц также может быть объединён с соседом в блок по 1024 страницы, если таковой сосед, конечно, имеется.
Формально описать правила для "приятелей", которых следует объединить, можно так:
- Оба блока одинакового размера.
- Оба блока находятся в одном непрерывном диапазоне физических адресов.
- Физический адрес первой страницы в первого блока является произведением
2 * [размер блока] * [размер страницы].