Введение
Данная заметка должна поднять завесу тайны над сущностью ядра Linux, которая называется “generic net estimator”. Зачем это нужно, и как этим пользоваться?
Ладно, дальше всё равно будет каша, потом структурирую.
Точка входа:
gen_new_estimator() в net/core/gen_estimator.c. Обещает создать новый estimator. Принимает на вход указатель на статистику, в том числе per cpu.
Вот структура статистики:
struct gnet_stats_basic_packed {
__u64 bytes;
__u32 packets;
} __attribute__ ((packed));
...
struct gnet_stats_basic_cpu {
struct gnet_stats_basic_packed bstats;
struct u64_stats_sync syncp;
};Так, думаю к анализу можно подойти с предметной стороны: мы собираем статистику, но какую?
Итак, рассмотрим предметную область. Активно rate estimator используется в net/sched для отслеживания утилизации очередей и их классов. Речь, конечно, про исходящие очереди. Поэтому для нас точкой входа будет метод dev_queue_xmit().
Рассмотрим конкретный пример — транзитный IPv4 трафик. Метод ip_forward() будет перенаправлять пакеты, приходящие на один интерфейс, на другой интерфейс, через который доступен адресат пакета. Для этого он использует метод dev_queue_xmit(). На самом деле последний метод может дёрнуть рутину вставки пакета сразу в аппаратную очередь через dev_hard_start_xmit(), но только в случае, если у данной очереди не определён метод enqueue: такое может быть, если на этой очереди стоит дисциплина обработки noqueue. А если метод enqueue определён, то будет вызвана рутина __dev_xmit_skb().
Задача метода __dev_xmit_skb() заключается в том, чтобы подкладывать пакеты в очередь методом enqueue и запускать её исполнение через __qdisc_run(). При этом захватывается блокировка самого struct Qdisc. И, что логично, в процессе работы очереди, независимо от дисциплины обработки, пакеты будут выниматься из этой очереди с помощью метода dequeue. Как правило, метод dequeue при этом инкрементирует статистику самой очереди через qdisc_bstats_update(). Исключением из этого правила является, например, noop_dequeue(), который, хотя и является наилучшей реализацией этого метода, никем не используется, даже дисциплиной noop.
Разберём конкретную реализацию на примере дисциплины htb. Ниже по стеку от метода htb_dequeue(), в htb_dequeue_tree() также ведётся учёт статистики по классам. Для этого используется стандартный метод bstats_update(), в который передаётся экземпляр статистики конкретного класса.
Таким образом, каждый пакет капает в счётчики struct gnet_stats_basic_packed и очереди, и классов. Это мы разобрались со статистикой. Однако мы не ради статистики же здесь собрались. Раз это “rate estimator”, то нам, наверно, интересны параметры именно потока, числа в динамике. Маловато полей в нашей структуре статистики для такого. Если исключить инициализацию, то единственное упоминание estimator находится в методе dump_class, который передаёт эту статистику в пользовательское пространство — это нам неинтересно. Тогда взглянем на инициализацию.
Для начала рассмотрим конфигурирование дисциплины:
$ tc qdisc help
...
[ estimator INTERVAL TIME_CONSTANT ]После ключевого слова estimator необходима передача двух параметров:
INTERVAL— задаёт интервал измерений. КаждыеINTERVALсекунд происходит защёлкивание статистики: находится разница между текущей статистикой и предыдущей, приводится к одной секунде, и сохраняется;TIME_CONSTANT— задаёт период показаний. Показываемая статистика будет справедлива для последнихTIME_CONSTANTсекунд, с некоторыми оговорками: хвост у функции усреднения будет очень длинным.
Всё, теперь можно пойти сразу в ядро (нам же неинтересен разбор строк в iproute2). Начнём с точки входа qdisc_create() — данная рутина создаёт дисциплину обработки и прикрепляет её к интерфейсу. Один из параметров, которые приезжают по netlink, является tca[TCA_RATE] — этот атрибут несёт в себе экземпляр структуры struct gnet_estimator:
struct gnet_estimator {
signed char interval;
unsigned char ewma_log;
};Вот и наши параметры, которые мы писали при создании qdisc. Далее они пойдут в метод gen_new_estimator() — этот метод заполнит экземпляр структуры struct net_rate_estimator, в частности:
seqcount_init(&est->seq); // Инициализируем механизм разделения доступа к общим ресурсам `seqcount`
intvl_log = parm->interval + 2; // Приводим интервал к степени коэффициента, подробности см. ниже
est->bstats = bstats; // Схороняем структуру статистики `struct gnet_stats_basic_packed`
est->stats_lock = stats_lock; // Схороняем пользовательскую блокировку spinlock
est->running = running; // Схороняем пользовательский seqcount
est->ewma_log = parm->ewma_log; // Схороняем коэффициент EWMA
est->intvl_log = intvl_log; // Схороняем коэффициент интервала логирования
est->cpu_bstats = cpu_bstats; // Схороняем per-cpu счётчики (их может и не быть)
est_fetch_counters(est, &b); // Если нам передали не пустые счётчики, то неплохо было бы считать rate с этого момента
est->last_bytes = b.bytes; // Схороняем байт, которые уже были переданы
est->last_packets = b.packets; // Аналогично схороняем пакеты
est->next_jiffies = jiffies + ((HZ/4) << intvl_log); // Высчитываем время по системным часам, когда должен сработать таймер
setup_timer(&est->timer, est_timer, (unsigned long)est); // Инициализируем таймер
mod_timer(&est->timer, est->next_jiffies); // Заводим таймер на вычисленное времяЕщё раз по поводу параметров. Зачем нужны эти манипуляции вроде parm->interval + 2 и HZ/4: дело в том, что минимальный интервал опроса составляет 250 мс, а максимальный интервал — 8 секунд. При этом, все интервалы должны являться степенью двойки. Грубо говоря, интервалы от 1/4 секунды до 8 секунд соответствуют степеням двойки от -2 до 3. А в арифметике нам гораздо дешевле использовать операции побитового сдвига. Но если бы мы сдвинули биты на -2, то получили бы корень, а не отрицательную степень. Поэтому мы в compile-time вычисляем четверть от HZ (герцы, а не хз — частота системных часов, кол-во тиков за одну секунду) и сдвигаем его на разницу между задуманной степенью двойки и значением -2. Соответственно, est->intvl_log и хранит значение, на которое мы сдвинем четвертинку HZ.
С инициализацией мы разобрались, в нашей голове уже должна быть картина: вот мы проинициализировали структуру estimator, схоронили указатель на статистику, которую будем пинать вне кода estimator, а estimator теперь должен как-то сам следить за нашей статистикой. И даже догадываемся, что следить он будет в рутине, которую мы привязали к таймеру. Но как именно он это будет делать?
Разберём рутину est_timer(). Ну, первым делом нам, конечно, нужно получить обновлённые счётчики и найти разницу. А чтобы эту разницу усреднить и сгладить за заданный временной период, применим некоторые манипуляции. И не забудем обновить запомненные значения статистики для следующей итерации. Проиллюстрирую код:
est_fetch_counters(est, &b);
brate = (b.bytes - est->last_bytes) << (10 - est->ewma_log - est->intvl_log);
brate -= (est->avbps >> est->ewma_log);
rate = (u64)(b.packets - est->last_packets) << (10 - est->ewma_log - est->intvl_log);
rate -= (est->avpps >> est->ewma_log);
write_seqcount_begin(&est->seq);
est->avbps += brate;
est->avpps += rate;
write_seqcount_end(&est->seq);
est->last_bytes = b.bytes;
est->last_packets = b.packets;На первый взгляд код сложный, если с математикой тесно не знаком. А если немного знаком, то точно голову сломаешь, пытаясь найти здесь EWMA из википедии. На самом деле суть экспоненциальности в том, чтобы с каждой итерацией применять вес снова и снова. Ну здесь мы по сути применяем вес не на слагаемые, а на разницу между величинами, на которую изменится среднее значение.
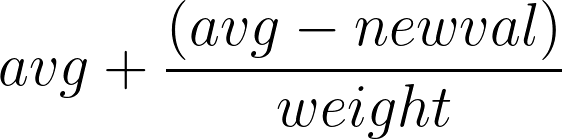
Но если мы используем побитовый сдвиг, то это значит, что весом могут быть только отрицательные степени двойки. Единственная не закрытая оговорка заключается в том, что этот avg мы храним сдвинутым на 8, т.к. нам новое значение величины нужно ещё к одной секунде привести и не встретить переполнение через нижнюю границу.
И последнее, вишенка на торте: чтение статистики. Оно происходит через функцию gen_estimator_read(). Она очень простая, нужно просто взять наши значения и сдвинуть их обратно на восемь в младшую сторону. Конечно, снова воспользовавшись est->seq для разделения доступа к данным. Раз уж мы разбирали на примере работы с qdisc, то предлагаю ознакомиться с методами dump_class классовых дисциплин обслуживания очередей в каталоге net/sched и tc_fill_qdisc().